

JAKARTA - Kontroversi baru kembali muncul di dunia kecerdasan buatan (AI). Kali ini, Meta dituduh melatih model bahasa besar (LLM) Llama, yang mendukung Meta AI, menggunakan konten bajakan yang diperoleh dari torrent. Kasus ini menjadi salah satu gugatan hak cipta pertama terhadap perusahaan teknologi terkait pelatihan AI.
Menurut laporan Wired, Meta menghadapi gugatan pada tahun 2023 dengan tuduhan menggunakan konten bajakan untuk melatih Llama. Kasus yang dikenal sebagai "Kadrey et al. v. Meta Platforms" ini diajukan oleh penulis Richard Kadrey dan Christopher Golden, yang menuduh Meta menggunakan konten berhak cipta tanpa izin.
Hingga saat ini, Meta telah menyerahkan dokumen dengan informasi yang disunting ke pengadilan. Namun, Hakim Vince Chhabria dari Pengadilan Distrik Amerika Serikat untuk Distrik Utara California memerintahkan agar dokumen asli dipublikasikan – dan akhirnya terungkap ke publik.
Dokumen tersebut menunjukkan percakapan antara karyawan Meta tentang Meta AI dan Llama. Dalam salah satu percakapan, seorang insinyur mengatakan bahwa "mengunduh torrent dari laptop perusahaan [Meta] terasa tidak benar," yang memperkuat dugaan bahwa perusahaan menggunakan konten bajakan untuk melatih AI-nya. Percakapan lain mengindikasikan bahwa "MZ" (Mark Zuckerberg) memberikan persetujuan atas penggunaan materi bajakan.
Bukti menunjukkan bahwa Meta menggunakan konten dari LibGen, sebuah perpustakaan besar berisi buku, majalah, dan artikel akademik bajakan. LibGen didirikan di Rusia pada tahun 2008 dan telah menghadapi berbagai gugatan hak cipta, meskipun operatornya tetap anonim. Selain itu, Meta dilaporkan menggunakan konten dari perpustakaan bayangan lainnya untuk pelatihan AI.
Meta berargumen bahwa mereka menggunakan materi publik di bawah doktrin hukum “fair use,” yang memungkinkan penggunaan konten berhak cipta tanpa izin dalam situasi tertentu. Meta mengklaim bahwa mereka hanya "menggunakan teks untuk memodelkan bahasa secara statistik dan menghasilkan ekspresi asli."
BACA JUGA:
-
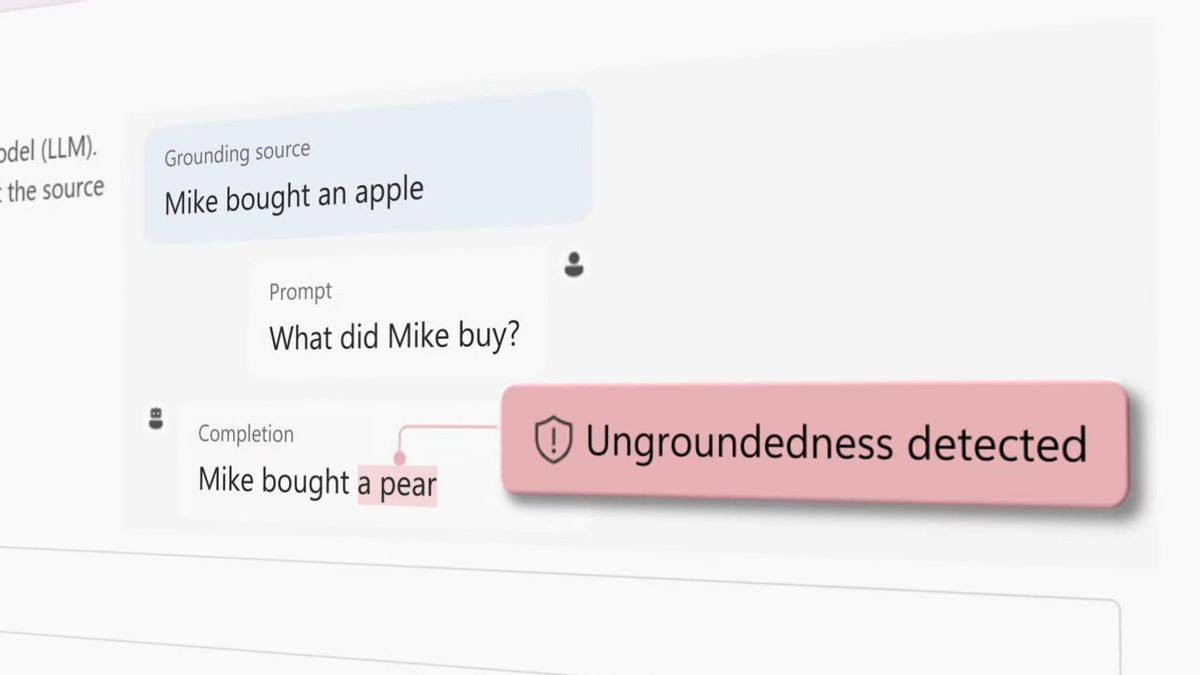
![]() | Teknologi
| Teknologi
Microsoft Luncurkan Fitur Koreksi untuk Atasi Kesalahan Penulisan AI
25 September 2024, 19:30 -
![]() | Teknologi
| Teknologi
Sennheiser Rilis Spectera, Teknologi Bidirectional Wideband Nirkabel Pertama di Dunia
25 September 2024, 20:30 -
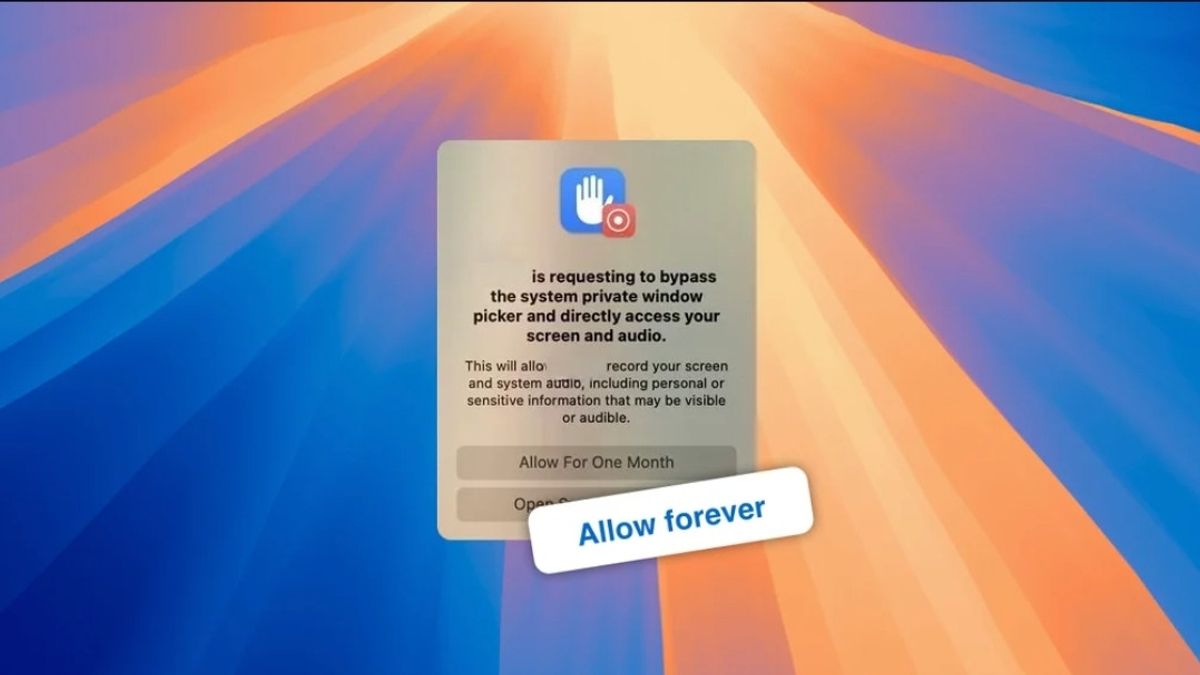
![]() | Teknologi
| Teknologi
Amnesia, Aplikasi untuk Atasi Gangguan Izin Perekaman Layar di macOS Sequioa
25 September 2024, 21:10 -
![]() | Teknologi
| Teknologi
Near Protocol Catatkan Kenaikan 50% dalam Sebulan, Ini Faktor Pendorong Utama!
25 September 2024, 22:00


Kasus Serupa
Ini bukan pertama kalinya perusahaan teknologi besar dituduh melatih model AI dengan konten berhak cipta. Tahun lalu, investigasi mengungkap bahwa model OpenELM buatan Apple mencakup subtitle dari lebih dari 170.000 video YouTube.
Namun, Apple kemudian menjelaskan bahwa OpenELM adalah model sumber terbuka untuk tujuan penelitian dan bukan bagian dari database yang digunakan oleh Apple Intelligence. Menurut Apple, fitur AI mereka dilatih menggunakan "data berlisensi, termasuk data yang dipilih untuk meningkatkan fitur tertentu, serta data publik yang dikumpulkan oleh web-crawler kami."
Sementara itu, banyak penerbit besar seperti The New York Times dan The Atlantic memilih untuk tidak berbagi konten mereka untuk pelatihan Apple Intelligence.
Kasus ini menjadi perhatian besar bagi dunia teknologi dan hukum, terutama dalam menentukan batasan penggunaan data berhak cipta untuk melatih AI.
Tag Terpopuler
#prabowo subianto #donald trump #banjir #imlek #palestina #pagar laut tangerangPopuler




Terkait






